
What does it actually cost to run CTI with an AI agent?
May 13, 2026
Modern deep research models can do real threat intelligence work. Before scaling that approach across a team, here is an honest accounting of the costs that don't show up on the invoice.
It is a fair question to ask in 2026. The frontier models are good. Deep research agents will autonomously plan a search, read dozens of pages, extract entities, and produce a brief that looks credible. So if a deep research agent can read threat reports, extract IOCs, and synthesise actor profiles, why pay for a CTI feed?
The honest answer is that you can build a CTI capability this way. The harder answer is what it actually costs once you account for the work that does not appear on the API bill. Most of the cost is below the waterline.
The visible cost: the model bill
This is the easy part to estimate. As of April 2026, Gemini Deep Research’s standard task processes around 250,000 input tokens and 60,000 output tokens, runs about 80 web searches, and lands at around US$2 per task. The Max tier scales those figures up to roughly 900,000 input tokens, 80,000 output tokens, and 160 searches, at $3 to $7 per task at current rates. Multiply either of those by every analyst question, every detection enrichment, every hunt hypothesis, every internal team, every day, and the per-query cost compounds quickly.
The structural reason is that agents are not human users. A human analyst makes a few queries every few minutes. An agent processing a single research task can fire off hundreds in seconds, each one re-deriving meaning from raw text from scratch. The same threat report gets re-read on every session. The same processing work gets re-done.
That is the visible bill. The rest is below the waterline.
The freshness tax
LLMs ship with a frozen knowledge cutoff. Anything that occurred after the training data was collected is invisible to the model unless retrieved through external tools. The effective cutoff, the date beyond which the model demonstrably stops knowing things, is often earlier than the reported one because of how training corpora are deduplicated. Researchers at Johns Hopkins found these effective cutoffs can differ from the advertised dates.
For threat intelligence this is structurally awkward. New malware families, new infrastructure, new TTPs surface every day. Recent academic work on LLM-assisted CTI specifically found that specialised cyber agents struggle to generalise to emerging threat patterns.
Web search as a freshness fix has its own structural limit: it surfaces what is findable, not what is authoritative. A general-purpose search engine ranks pages by signals like inbound links, click-through, and recency of indexing. The threat research that actually advances the field is often the opposite shape: a specific piece of work read by maybe a hundred specialists worldwide, posted to a researcher’s blog, a CERT advisory, a closed mailing list, or a Telegram channel. It does not rank, and a general LLM web search may not surface it. In practice, threat profiles built this way still end up flagged for manual review because the data behind them is not always reachable through normal web search. The agent finds the popular write-ups; the primary research that matters is somewhere else.
The iceberg cost: every output needs a freshness check. Did the agent find the most recent variant, or the one it remembered from training? Was its web search comprehensive, or did it stop at the first three plausible results? An analyst either does this verification step on every brief, or accepts the risk of acting on stale intelligence.
The extraction tax
Threat reports are messy. They mix narrative prose, defanged indicators, screenshot-only IOCs, footnoted CVEs, mixed languages, vendor-specific actor names, and footnotes that look like indicators but are not.
In a 2025 evaluation, researchers at Georgia Tech and the University of Georgia found that popular threat report IOC exchanges like AlienVault automatically extract IOCs from unstructured reports with both precision and recall below 80%. LLM-based extraction can do better, but recent research consistently lands on a human-in-the-loop pattern. The same paper introduced a system called LANCE that reduced analyst labelling time on threat report IOCs by 43%, with the analyst still doing the validation step.
The same problem appears at scale. A separate 2025 evaluation tested three frontier LLMs (gpt4o, gemini-1.5-pro, mistral-large-2) on 350 real APT threat reports averaging 3,009 words each, against an open-source dataset structured in STIX. Precision dropped to 0.76 on full reports compared to the 0.83 to 0.89 reported in prior LLM-CTI papers that tested on inputs averaging 18 to 174 words. Few-shot learning and fine-tuning made performance worse, not better. Recall on campaign extraction with fine-tuned gpt4o fell to 0.58, meaning 42% of campaigns were missed. LLM performance on CTI tasks degrades substantially when moving from short test inputs to real-world report sizes.
A 43% time reduction is genuine value. It is also still an analyst doing review work on every report. Errors in extraction propagate into your detection pipeline. A misclassified IOC is not just noise. It is potentially a block on legitimate infrastructure, or a missed detection on a real C2.
The iceberg cost: validation hours. Whatever the agent extracts has to be checked, normalised, and reconciled against existing data before it can drive a detection.
The hallucination tax
Even with retrieval grounding, frontier models still hallucinate.
A 2025 empirical study of LLM behaviour on threat intelligence tasks documented systematic failure across three categories the authors call spurious correlation, contradictory knowledge, and constrained generalisation. The paper argues the underlying problem is not generic model hallucination but the threat landscape itself: heterogeneous, volatile, and fragmented in ways standard LLM evaluation rarely captures.
Broader benchmarks point in the same direction. The HalluHard multi-turn benchmark, published in 2026, tested frontier models on legal, research, medical, and coding domains. Even the strongest configuration tested, Anthropic’s Opus 4.5 with web search enabled, hallucinated in roughly 30% of cases. The same model without retrieval crossed 60%.
Citation accuracy work from adjacent domains tells a consistent story. Studies have measured fabrication rates spanning a fivefold range, from around 11% to almost 57%, depending on model, prompt, and domain. An earlier study by Walters and Wilder found 18% of GPT-4 generated citations were fabricated, and 24% of the real ones contained substantive errors. In a 2024 evaluation against systematic reviews, hallucination rates ran 28.6% for GPT-4, 39.6% for GPT-3.5, and 91.4% for Bard.
Models keep getting better at this. Single-turn, well-grounded prompts hallucinate less than multi-turn agentic loops. The shape of the failures across CTI, legal, academic citation, and medical work is different. The underlying problem is the same: confident output that is not actually grounded.
For CTI specifically, the artefacts that get hallucinated translate directly into actioned decisions. Invented CVEs, attributed campaigns that never existed, fabricated infrastructure, confident statements about actors stitched together from adjacent reports the model has read. A hallucinated finding in a threat brief is worse than no finding, because it gets actioned.
The iceberg cost: every claim in every output needs to be source-checked. Time spent recovering from a hallucinated lead is unbounded. The analyst who chased an attribution to a non-existent infrastructure cluster does not get those hours back.
The verifiability tax
Even when an AI agent gets the right answer once, it may not get the same answer again. LLMs are non-deterministic by design. The same prompt, the same input, the same model can produce different outputs across sessions.
The 350-report evaluation cited above measured this directly. The same model, prompted ten times with identical inputs and the maximum determinism settings (temperature zero, fixed seed), still produced confidence-interval widths of up to 0.06 on key entity extraction tasks. In one case, generating CVE codes from APT names produced a recall confidence interval of 0.19 to 0.25: the same input could miss anywhere from 75% to 81% of the CVEs depending on the run.
Worse, the same paper found the models were not calibrated. The confidence scores reported by the models did not match actual correctness rates. After fine-tuning, expected calibration error reached 0.91 for CVE generation and Brier score reached 1.00 for attack vector generation. The authors describe this as complete misalignment between confidence and correctness. An automated CTI pipeline that decides whether to act on a finding based on the model’s own confidence score is, in this regime, choosing close to randomly.
For threat intelligence work this means two things. First, an automated pipeline cannot trust the model’s confidence score to triage findings. Second, an analyst cannot reproduce yesterday’s brief by re-running yesterday’s prompt. The output drifts. For audit, repeatability, and trust, that is a structural problem.
The iceberg cost: every conclusion needs to be re-checked against the data, not against yesterday’s output. The pipeline needs deterministic validation steps to compensate for non-deterministic generation. This is why mature CTI pipelines combine deterministic methods (regex, schema-based extraction, ML classifiers) with LLMs and human review, rather than relying on LLMs alone. Part 2 of this series will look at what a hybrid data layer of this kind actually involves.
The orchestration and maintenance tax
This is the cost most teams underestimate going in. Even assuming the model and its retrieval layer behave perfectly, there is still a pipeline to build and maintain around it.
Prompts have to be written, tested, and iterated against edge cases. Source lists need to be maintained: which CERTs, which vendor blogs, which sandbox feeds, which language-specific sources. Schemas drift between runs unless they are constrained. The agent has no memory across sessions, so deduplication against prior intelligence is your problem. Non-English sources need translation handling. Output is prose, not STIX, so there is a normalisation step before anything reaches a TIP or SIEM. Detection rules have to be derived, not just IOC lists.
None of this is novel work. It is the standard CTI processing pipeline. The question is whether your team’s time is best spent building and maintaining one, or using one.
Where this leaves the build versus buy question
The intelligence cycle has always separated collection and processing from analysis and dissemination. There is a reason for that. Collection and processing are largely deterministic, repeatable, and benefit from being done once at scale. Analysis is contextual, situational, and benefits from being done specifically for the audience and decision at hand.

AI does not change that separation. It changes which side of the line is the right place for AI to spend its tokens. The collection and processing layer of CTI is exactly the kind of work that benefits from being done once, deterministically, and reused across teams and sessions. The analysis and action layer is where session-specific reasoning genuinely earns its tokens: triage logic, hunt hypothesis generation, detection rule drafting, attribution synthesis, prioritisation against your environment.
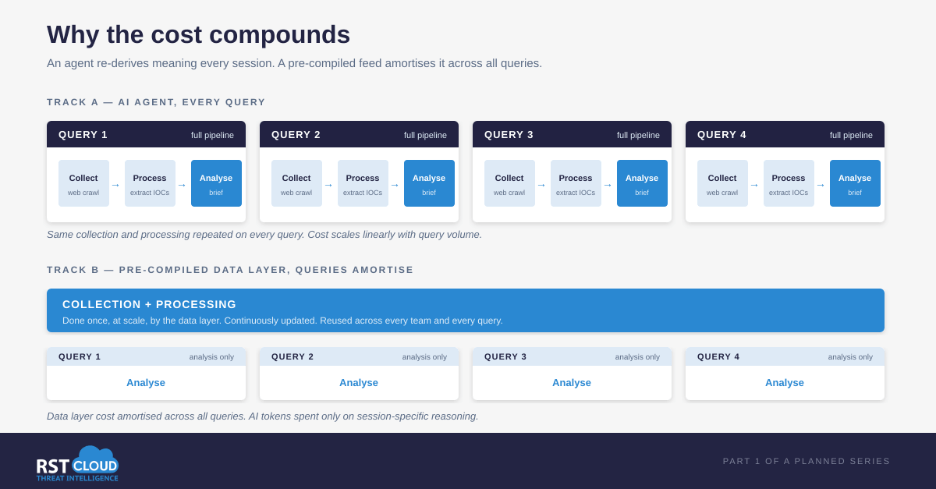
This is not unique to CTI. The same logic explains why most security teams use VirusTotal rather than building their own multi-engine scanning infrastructure, why they use a passive DNS provider rather than running their own resolver fleet, and why they use a sandbox service rather than maintaining their own. Specialisation at the data layer is a long-running pattern in security tooling.
The honest questions
If you are weighing whether to run CTI on an AI agent versus subscribe to a feed, the cost comparison is not the model bill versus the licence fee. The questions worth asking are:
How much of your analyst time will go to validating AI output versus analysing it? How much engineering capacity can you commit to maintaining the pipeline around the agent: prompts, sources, schemas, deduplication, normalisation? What is your tolerance for a hallucinated finding making it into a brief? Is your team’s comparative advantage in CTI collection, or in CTI analysis applied to your environment?
A rough way to test it: estimate the analyst hours per week your team would spend on freshness checks, IOC validation, source-checking on AI outputs, and pipeline maintenance. Multiply by loaded hourly rate. Add the per-task model and search costs from the visible-cost section, multiplied by expected query volume. Compare to a feed subscription quote. For most teams running production CTI volume, the direct cost comparison favours the feed before indirect costs (chasing hallucinated leads, opportunity cost of analyst time spent on collection rather than analysis) are added.
There are real cases where the build path works. Teams with mature ML engineering depth and dedicated data platform engineers can absorb the orchestration tax. Closed-scope CTI work, where source coverage is bounded and known (a specific industry, region, or threat actor portfolio), reduces the source-list maintenance burden. Use cases where individual findings drive situational awareness rather than directly feeding detection pipelines tolerate higher hallucination floors. Organisations with existing investment in data platform infrastructure already have the building blocks. And some advanced threat hunting work specifically requires sources or framings that no vendor feed will cover. None of these are edge cases, and the build path can be the right answer when they apply.
For other teams, the iceberg cost makes the buy path obviously cheaper, and the comparative advantage is on the analysis side anyway.
AI is genuinely strong at the analysis and action layer when the data layer is solid. The interesting question is no longer whether AI changes CTI. It is which layer of the stack your team is best placed to own, and what a data layer built for AI-assisted CTI should actually look like.
Author's note: this is the first in a planned series on AI-assisted CTI. Part 2 will look at what a good data layer for AI-assisted CTI actually looks like, including structured data, schema choices, and why pre-extracted entities reduce hallucination surface. I work at RST Cloud, where we operate on the data layer side of this question. Feedback and counter-arguments welcome.
Ready to explore how AI-powered CTI can support your security operations?
Try the capabilities of our RST AI Assistant in your day-to-day workflow and see how structured, enriched threat intelligence can accelerate analysis and decision-making.
The research and article were authored by Alexander Gould.
References
- Aglawe, A. Gemini Deep Research pricing: cost per task 2026. TokenCost, April 2026. https://tokencost.app/blog/gemini-deep-research-agent-cost
- Cheng, J., Marone, M., Weller, O., Lawrie, D., Khashabi, D., Van Durme, B. Dated Data: Tracing Knowledge Cutoffs in Large Language Models. Johns Hopkins University. arXiv:2403.12958, 2024. https://arxiv.org/abs/2403.12958
- Meng, Y. et al. Uncovering Vulnerabilities of LLM-Assisted Cyber Threat Intelligence. arXiv:2509.23573, 2025. https://arxiv.org/abs/2509.23573
- Froudakis, E., Avgetidis, A., Frankum, S. T., Perdisci, R., Antonakakis, M., Keromytis, A. Revealing the True Indicators: Understanding and Improving IoC Extraction From Threat Reports. Georgia Institute of Technology and University of Georgia. arXiv:2506.11325, 2025. https://arxiv.org/abs/2506.11325
- Mezzi, E., Massacci, F., Tuma, K. Large Language Models are unreliable for Cyber Threat Intelligence. VU Amsterdam and TU Eindhoven. arXiv:2503.23175, 2025. https://arxiv.org/abs/2503.23175
- Fan, D., Delsad, S., Flammarion, N., Andriushchenko, M. HalluHard: A Hard Multi-Turn Hallucination Benchmark. EPFL. arXiv:2602.01031, 2026. https://arxiv.org/abs/2602.01031
- Naser, M. Z. How LLMs Cite and Why It Matters: A Cross-Model Audit of Reference Fabrication in AI-Assisted Academic Writing and Methods to Detect Phantom Citations. Clemson University. arXiv:2603.03299, 2026. https://arxiv.org/abs/2603.03299
- Walters, W. H. and Wilder, E. I. Fabrication and errors in the bibliographic citations generated by ChatGPT. Scientific Reports 13, 14045, 2023. https://www.nature.com/articles/s41598-023-41032-5
- Chelli, M. et al. Hallucination Rates and Reference Accuracy of ChatGPT and Bard for Systematic Reviews: Comparative Analysis. J Med Internet Res 2024;26:e53164. https://www.jmir.org/2024/1/e53164/