
What a good data layer for AI-assisted CTI actually looks like
Jun 30, 2026
Part 2 of a planned series. Part 1 looked at the iceberg costs of running CTI on an AI agent. This part looks at the architecture that makes AI, and automation, useful instead.
Part 1 ended on a question: which layer of the stack is your team best placed to own, and what does a data layer built for AI-assisted CTI actually look like? This answers the second half.
The argument is broader than AI. The same structural failures that break AI agents also break SOAR playbooks, SIEM correlation, and any pipeline that has to act on threat intelligence without an analyst in the loop. Structured data isn’t an AI investment; it’s the foundation everything downstream depends on. Each section below starts with a failure mode you have probably seen, then names the architectural choice that prevents it. The working example is STIX 2.1, because it is the most widely used open standard for CTI exchange, but the principles apply to any properly engineered schema.
Structured data isn’t just an AI problem
A SOC pulls a threat report and wants to do three things: block the indicators, fire a SOAR playbook to enrich and triage, and feed context to the analyst’s queue. None of those need AI. They need structured indicators with type, confidence and source attached. If the report is prose, someone, an analyst or an LLM, has to parse it first. If it’s structured, the indicators route straight to the tools that need them.
Most CTI workload is ingestion and routing, not reasoning. Part 1 cited Gemini Deep Research at $2 to $7 per task; a deterministic SOAR enrichment step costs a fraction of a cent. Pushing routine ingestion through an LLM is paying reasoning prices for clerical work. The principle: AI is the right tool when reasoning is required, automation when it isn’t, and both depend on the same precondition, structured input. That is why structured CTI is a no-regret investment, it pays off across AI, automation and analyst workflows at once.
The shape problem
An analyst asks an agent to summarise recent activity attributed to APT41. It pulls articles calling the group APT41, Wicked Panda, BARIUM and Brass Typhoon. The agent now has four sources that look like four actors, and the analyst either trusts its reconciliation (risky) or redoes it by hand (which defeats the point).
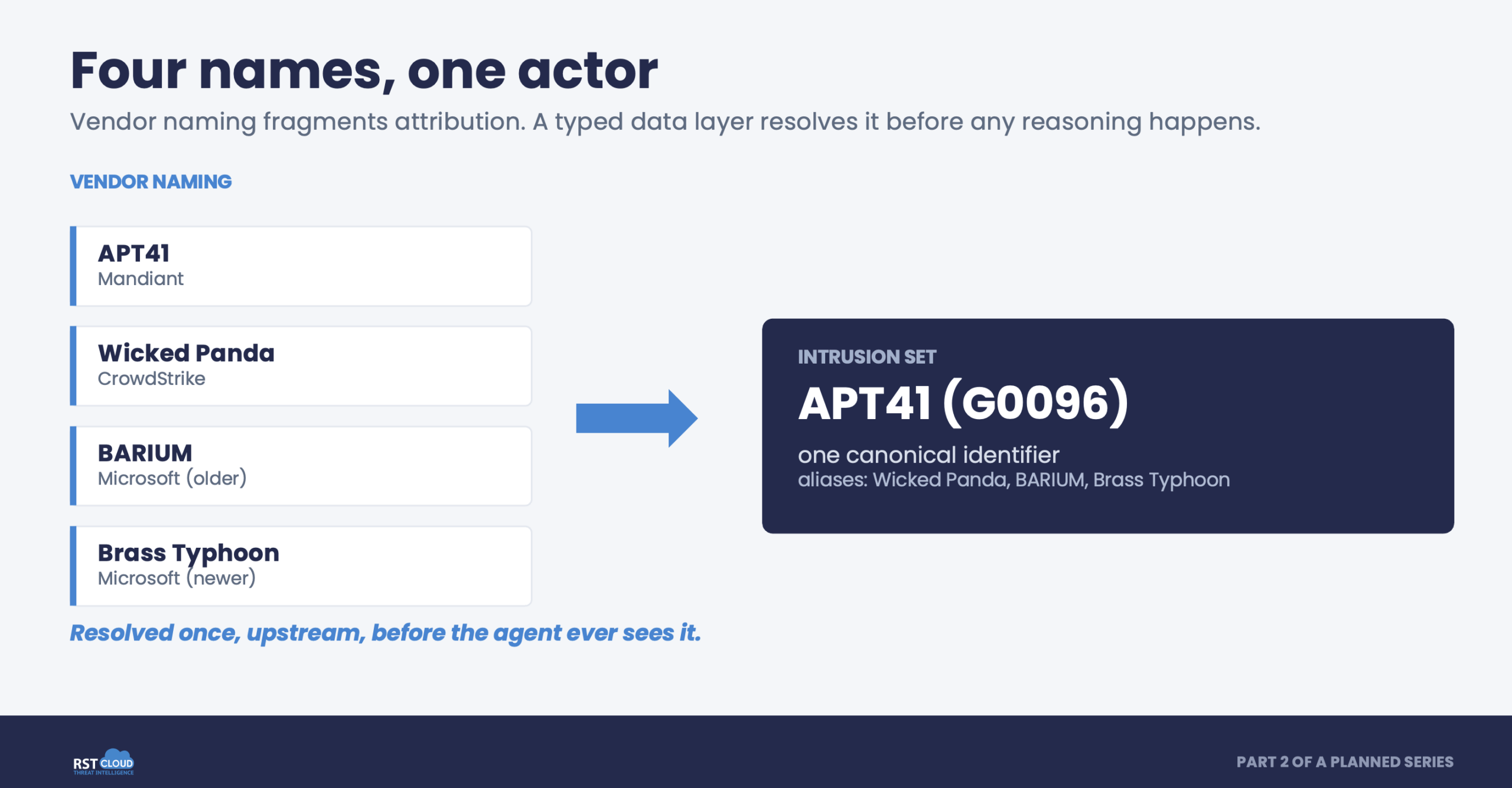
When an agent reads CTI from the open web it must parse, classify, extract, deduplicate and normalise before any reasoning happens, and every step compounds error. A 2025 evaluation by Mezzi, Massacci and Tuma measured this: extraction precision fell to 0.76 once inputs scaled to full-length reports, and confidence-interval widths reached 0.06 across ten identical runs on the same input.
A properly engineered data layer does those steps once, upstream. The four names resolve to one Intrusion Set object with aliases as a property, so the agent receives a typed entity, not four strings to guess about. The industry has conceded the problem: Microsoft and CrowdStrike published a joint threat-actor name mapping in June 2025, with Google Mandiant and Unit 42 contributing, precisely because naming inconsistency was slowing response.
This is also where the extraction tax from Part 1 goes. It doesn’t disappear, it moves. A data-layer provider pays it once per report, amortised across every consumer and backed by dedicated validation, rather than every team paying it again on every query.
Why structured beats unstructured for retrieval
Ask an agent what malware an actor uses against a blog post and it must infer association from prose, weighting attribution claims against passing mentions. Every step invites a hallucination. The same question against a typed graph is one traversal: find the Intrusion Set, follow the uses edges, return the list. The schema constrains what the agent can say, since a model retrieving a labelled relationship cannot invent a different one.
Recent research bears this out: retrieval against structured knowledge graphs produces meaningfully lower hallucination rates than embedding-only retrieval on knowledge-intensive tasks, because the graph constrains both what is retrieved and how it is composed. This matters more for CTI than for general retrieval. CTI is a small-data domain where the same intrusion sets, malware families and CVEs recur across hundreds of reports under vendor-specific names. Without normalisation, retrieval is guesswork; with it, it’s graph traversal.
Schema choices that matter
An in-house CTI database with a flat schema and free-text relationship fields handles “show every indicator attributed to actors targeting healthcare in the last 90 days” badly: string-matched joins, prose parsing for the right verb, and a sector tag that may not exist. The schema isn’t load-bearing for the questions analysts actually ask.
STIX 2.1, the OASIS standard, models entities as Domain Objects, observables as Cyber-observable Objects, and relationships as Relationship Objects with types from a recommended vocabulary rather than free text. A properly typed schema gives four things ad-hoc structures cannot:
- Typed identity: an Intrusion Set has a persistent identifier across reports, and vendor names are aliases on one object.
- Typed relationships: “uses” is an explicit edge, not a verb parsed from prose.
- Embedded provenance: objects carry the identity that produced them and the marking that governs sharing.
- Composability: one observable is reused across indicators rather than re-extracted each time.
STIX isn’t perfect: the Sighting object is awkward at telemetry volume, kill-chain phases are coarse next to ATT&CK (so most implementations carry both), and custom-object creep is a real interoperability tax. The point isn’t that STIX is the final answer; it’s that any working schema has to provide those four capabilities.
What enrichment buys you
An automation rule that blocks every IP in a report soon has half its block list full of CDN ranges and shared hosting. The design was wrong. A schema makes structure possible; enrichment makes it safe to act on. Three functions are load-bearing:
- Source confidence: a CERT advisory is not an anonymous Telegram post. Attaching confidence lets a rule or an agent weight inputs rather than treating them alike. The Mezzi evaluation also found calibration failure in current models, with expected calibration error reaching 0.91 on fine-tuned CVE generation, so if the model can’t self-calibrate, the data layer must.
- Scoring and decay: intelligence ages, and a malicious IP can be a sinkhole six months later. Time-based decay lets automation deprioritise old indicators and lets an agent prioritise current threats without doing the timeline reasoning itself.
- Noise filtering and deduplication: the same observation propagates across dozens of feeds. Without dedup, frequency misleads; without noise filtering, common-good infrastructure ends up blocked. This is the difference between a feed that improves your SOC and one that breaks it.
Provenance and auditability
A customer asks why you blocked an IP last Tuesday. The playbook fired on a feed entry, which referenced a report, which referenced another, which made a claim that was wrong, and two hours go by before anyone reaches the original error. The problem isn’t the error, it’s that the chain from action to evidence wasn’t traceable.
AI agents don’t preserve provenance by default, and automation tools don’t either unless the data layer hands it to them. STIX objects carry created and modified timestamps, a created_by_ref to an Identity, and external references with source URLs and hashes, so the chain back to source comes with the answer. That buys three things: audit, showing how you reached a conclusion; contestability, locating whether a wrong finding came from the data, the rule or the model; and repeatability, re-deriving yesterday’s brief tomorrow regardless of model drift. Part 1 noted that LLM output drifts across identical prompts, and provenance in the data layer is how you compensate.
What structured retrieval looks like in practice
Take “what is the latest activity attributed to this actor?” The unstructured path searches the web, reads the top few articles, parses prose, matches aliases and synthesises a paragraph: high token cost, low determinism, weak provenance, and freshness limited to what indexes well. The structured path queries a CTI API for the Intrusion Set matching any known alias and returns connected Campaign, Malware and Indicator objects by modified date with sources attached: low token cost, deterministic, structural provenance, as fresh as the last data-layer update.

The same structured response also serves automation that needs no AI step at all. The agent’s tokens go to reasoning (“given these campaigns, what’s the operational pattern, and what does it mean for our customer?”) rather than collection. That is what “AI tokens belong on the analysis layer” looks like in practice. One caveat: if the structured layer isn’t exposed through an API the agent can query mid-task, the agent falls back to the open web and the shape problem returns.
Where this leaves us
assisted CTI needs five things: a schema that types entities and relationships, enrichment that weights and ages claims, deduplication that resolves aliases, provenance that makes findings auditable, and an API that exposes all of it to retrieval. None are about the model; all are about the layer underneath. Part 1 argued most of the cost sits below the waterline; this is the counterpart, that most of what makes AI useful sits below the model.

With that layer in place, two things follow: automation handling routine ingestion and routing without burning tokens, and AI reasoning applied to the questions that actually need it. Most CTI workload is the first; the value AI adds is the second. Part 3 looks at exactly where that AI value shows up, where session-specific reasoning, hypothesis generation and analyst-facing synthesis earn their tokens.
The research and article were authored by Alexander Gould.
Author’s note: this is the second in a series on AI-assisted CTI. Part 1 covered the iceberg costs of running CTI on an AI agent; Part 3 will look at what AI is genuinely strong at once the data layer is solid. I work at RST Cloud, where we operate on the data-layer side of this question. Feedback and counter-arguments welcome.
References
1. Mezzi, E., Massacci, F., Tuma, K. Large Language Models are unreliable for Cyber Threat Intelligence. arXiv:2503.23175, 2025. https://arxiv.org/abs/2503.23175
2. Jakkal, V. Announcing a new strategic collaboration to bring clarity to threat actor naming. Microsoft Security Blog, 2 June 2025. https://www.microsoft.com/en-us/security/blog/2025/06/02/announcing-a-new-strategic-collaboration-to-bring-clarity-to-threat-actor-naming/
3. MITRE ATT&CK Group G0096 (APT41) and associated aliases (Wicked Panda, Brass Typhoon, BARIUM). https://attack.mitre.org/groups/G0096/
4. Li, M., Miao, S., Li, P. Simple Is Effective: The Roles of Graphs and Large Language Models in Knowledge-Graph-Based Retrieval-Augmented Generation (SubgraphRAG). arXiv:2410.20724, 2024. https://arxiv.org/abs/2410.20724
5. TOBUGraph: Knowledge Graph-Based Retrieval for Enhanced LLM Performance Beyond RAG. arXiv:2412.05447, 2024. https://arxiv.org/abs/2412.05447
6. STIX Version 2.1. OASIS Open, OASIS Standard, June 2021. https://docs.oasis-open.org/cti/stix/v2.1/os/stix-v2.1-os.html
7. Creating Custom STIX Objects for Cyber Threat Intelligence. dogesec, 2024. https://www.dogesec.com/blog/create_custom_stix_objects/